前言
最近电子商城慢sql问题引了小BOSS的重视,于是就打算给开发们搞一个表格,在表格里可以看到前一天阿里云数据库的慢sql。这一次我不打算用html邮件了,因为慢sql数量不固定,今天可能三个,明天可能五个,后天抽风可能就一百个。而html邮件的格式是要事先写死的,于是我就用pandas来做这个表格,直接生成一个html文件,通过访问浏览器去让开发看慢sql。
慢日志脚本
我要承认,阿里云自带的api在线调试工具真是一个好东西,有了它,脚本demo可以直接生成,地址是:https://api.aliyun.com/?spm=a2c4g.750001.952925.6.1QrDYe ,于是乎,阿里云获取慢日志脚本test.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#coding=utf-8
import json
from aliyunsdkcore import client
from aliyunsdkrds.request.v20140815 import DescribeSlowLogRecordsRequest
clt = client.AcsClient('这里是ak','这里是sk','这里是地域')
# 设置参数
request = DescribeSlowLogRecordsRequest.DescribeSlowLogRecordsRequest()
request.set_accept_format('json')
request.add_query_param('DBInstanceId', 'RDS的ID号')
request.add_query_param('StartTime', '2018-03-26T08:00Z') #3月26日早上8点开始
request.add_query_param('EndTime', '2018-03-27T08:00Z') #3月27日早上8点结束
request.add_query_param('DBName', '对应的数据库名')
request.add_query_param('PageSize', 100) #这个值只能是30/50/100
# 发起请求
response = clt.do_action_with_exception(request)
print response
#把json格式的返回值改成dict格式
slow_log=json.loads(response)
num = slow_log['TotalRecordCount']
Hostaddress = []
LockTimes = []
ParseRowCounts = []
QueryTimes = []
SQLText = []
#将有用的值做成list
if num < 100:
for i in range(0,num):
Hostaddress.append(slow_log['Items']['SQLSlowRecord'][i]['HostAddress'])
LockTimes.append(slow_log['Items']['SQLSlowRecord'][i]['LockTimes'])
ParseRowCounts.append(slow_log['Items']['SQLSlowRecord'][i]['ParseRowCounts'])
QueryTimes.append(slow_log['Items']['SQLSlowRecord'][i]['QueryTimes'])
SQLText.append(slow_log['Items']['SQLSlowRecord'][i]['SQLText'])
else:
for i in range(0,100):
Hostaddress.append(slow_log['Items']['SQLSlowRecord'][i]['HostAddress'])
LockTimes.append(slow_log['Items']['SQLSlowRecord'][i]['LockTimes'])
ParseRowCounts.append(slow_log['Items']['SQLSlowRecord'][i]['ParseRowCounts'])
QueryTimes.append(slow_log['Items']['SQLSlowRecord'][i]['QueryTimes'])
SQLText.append(slow_log['Items']['SQLSlowRecord'][i]['SQLText'])
这个response的格式是一个json,在www.json.cn里查看是这个样子: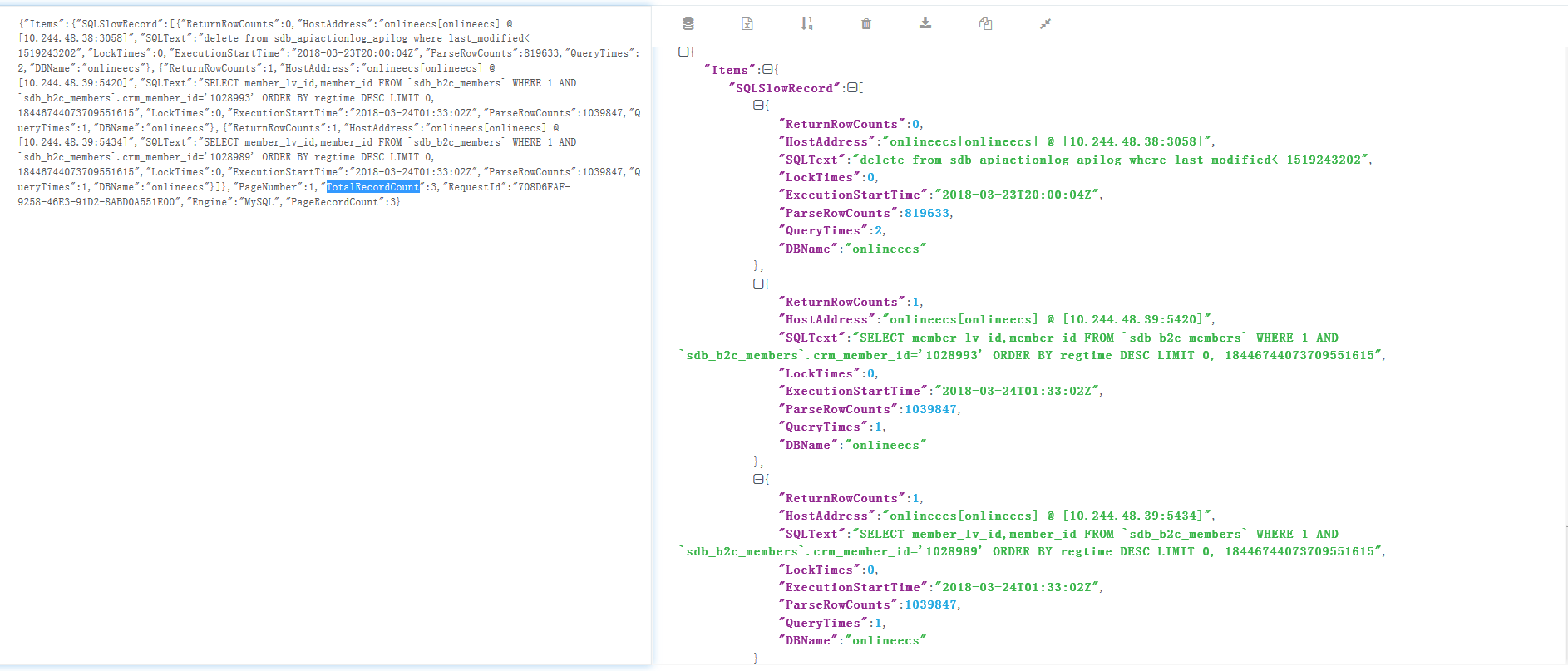
可以看到返回值里面TotalRecordCount就是总返回值,如果这个值大于PageSize,那么就会有第二篇,需要手动翻篇。所以我这里直接最大值就是100,一篇100已经够开发看了…
脚本如下
在上面的脚本里可以获取到所有慢sql的json格式,那么就可以再写一个脚本把json转化成html格式并且生成一个html文件,然后在nginx里直接把这个文件展示出来。既然用到了pandas库,那么就要先安装pandas,方法如下:
1
2
3
4pip install --upgrade pip
pip install pandas
如果有“Please upgrade numpy to >= 1.9.0 to use this pandas version”的反应,那么执行下一句
pip install -U numpy
生成html的整个脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#coding=utf-8
from test import Hostaddress,LockTimes,ParseRowCounts,QueryTimes,SQLText #从刚写的test.py里得到那些list变量
import pandas as pd
def convertToHtml(result,title):
#将数据转换为html的table
#result是list[list1,list2]这样的结构
#title是list结构;和result一一对应。titleList[0]对应resultList[0]这样的一条数据对应html表格中的一列
d = {}
index = 0
for t in title:
d[t]=result[index]
index = index+1
pd.set_option('max_colwidth',200) #默认的行长度是50,这里我调成了200
df = pd.DataFrame(d)
df = df[title]
h = df.to_html(index=False)
return h
if __name__ == '__main__':
result = [Hostaddress,LockTimes,ParseRowCounts,QueryTimes,SQLText]
title = [u'HostAddress',u'LockTimes',u'ParseRowCounts',u'QueryTimes',u'SQLText']
#生成一个叫biaoge.html
with open('/nginxhtml路径/biaoge.html', 'w') as f:
f.write(convertToHtml(result,title))
print "html文件已经生成!"
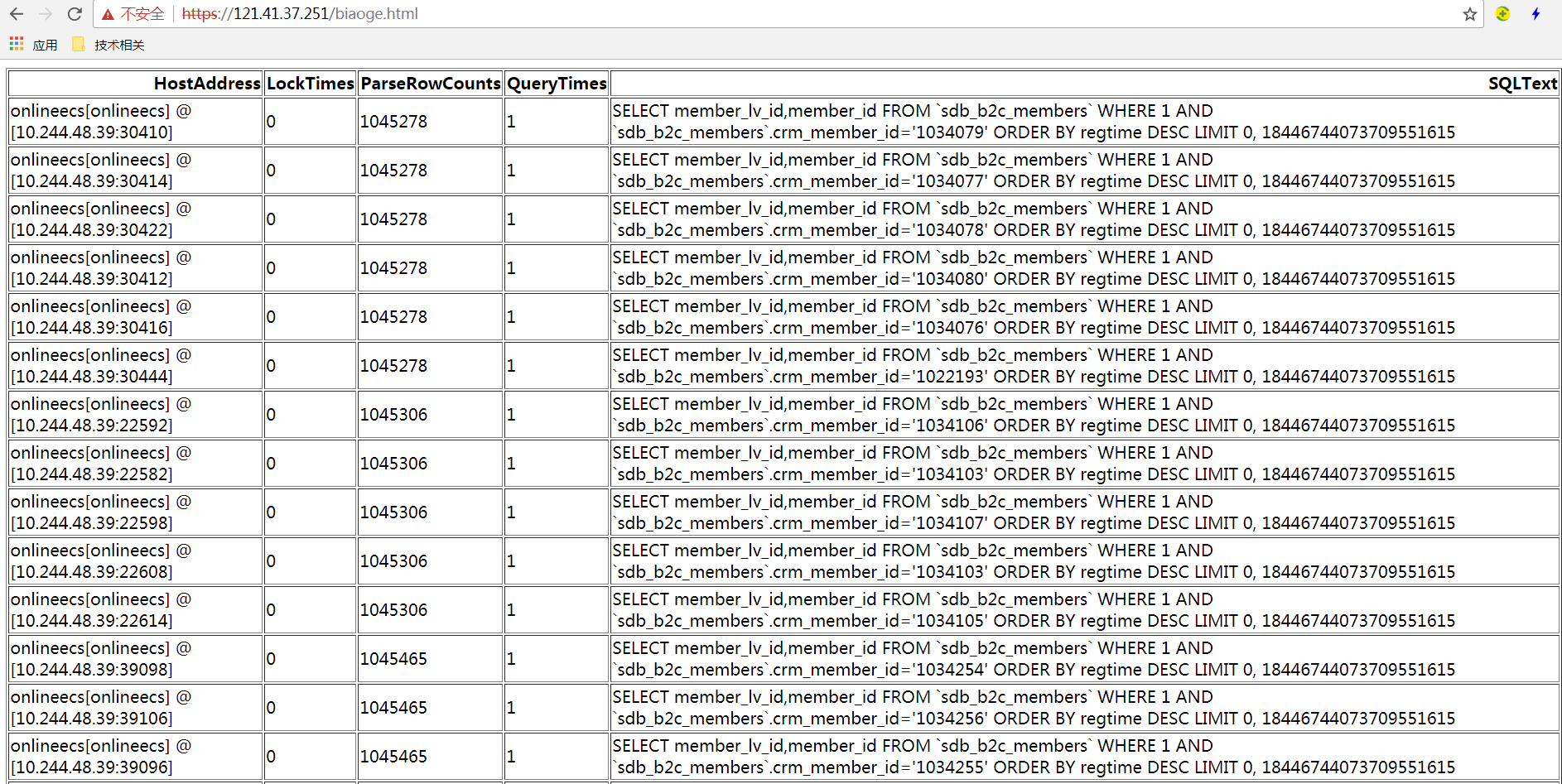
执行效果
将这个biaoge.html直接生成到nginx的html文件夹里,在浏览器里打开这个html就看到效果了,如图: