脚本在此
公司的商城需要添加一个脚本,这个脚本就是观察首页页面是否正常,虽然已经配置了zabbix监控网站是否200,但是有一些特殊的情况,比如网页可以打开但是页面是“file not found”,类似这样就需要被运维第一时间监控到然后通知开发。
原本我打算直接爬取整个首页然后与服务器里的index.html对比一下,如果不符合就报警,但是跟前端同事说了这个思路之后,前端说服务器上是没有index.html的,因为这个index.html是结合其他的php拼接的。前端说“只要能检测title正常就OK,一般来说title能获取到就证明系统是OK的,如果titleOK但是html内容获取不到就是前段代码的问题,跟系统无关”。于是我就写了这么一个爬虫脚本来获取网站title,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
#coding=utf-8
#这个脚本的用途是用来爬取商城首页title,然后判断是否正常
import requests,sys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8') #不然就会UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-4: ordinal not in range(128)
r = requests.get('https://www.lechange.com') #这里输入要爬的网站域名
r.encoding = requests.utils.get_encodings_from_content(r.content)[0]
soup = BeautifulSoup(r.text,'lxml') #这一步需要事前pip install lxml
print soup.title.string
说一下,如果在from bs4 import BeautifulSoup爆出ImportError: No module named 'bs4'是因为安装的库装错了,应该是pip install beautifulsoup4而不是pip install beautifulsoup。启动脚本效果如下: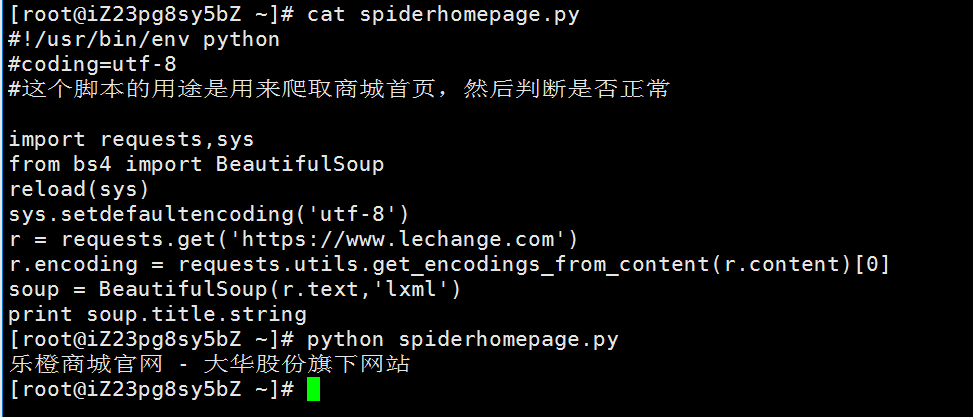
编码问题
上面那个脚本里的soup.title.string的类型是bs4.element.NavigableString,如果不用print那么它的形式是unicode的,如图:
这种现象并不新鲜,比如list在python2里一直都不是正常输出中文的,如图: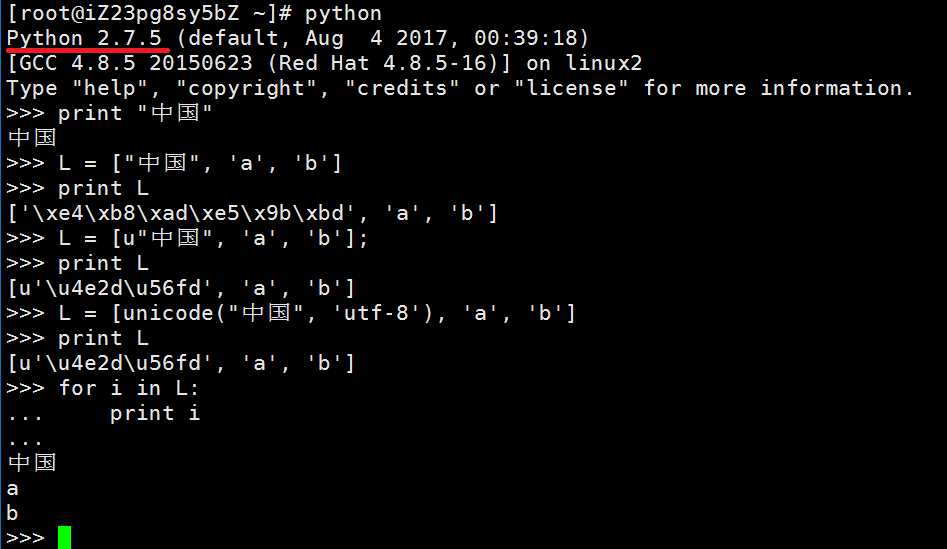
可见只有for in的时候才会正常编码,那么这样的情况怎么办?
最简单的方法,改用python3。不过上面那个脚本是可以直接把中文放到soup.title.string进行判断的。
安装python 3.6.4
首先要先安装相关依赖包yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make,其中readline-devel这个很重要,他是管方向键的,如果python运行的时候方向键不好使,那么就要yum install readline-devel安装,安装完毕后重新configure和make。
然后过程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17yum -y install epel-release #运行这个命令添加epel扩展源
#安装pip
yum install python-pip
pip install wget
wget https://www.python.org/ftp/python/3.6.4/Python-3.6.4.tar.xz
#解压
xz -d Python-3.6.4.tar.xz
tar -xf Python-3.6.4.tar
#进入解压后的目录,依次执行下面命令进行手动编译
./configure prefix=/usr/local/python3
make && make install
#将原来的链接备份
mv /usr/bin/python /usr/bin/python.bak
#添加python3的软链接
ln -s /usr/local/python3/bin/python3.6 /usr/bin/python
#测试是否安装成功了
python -V
更改yum配置,因为其要用到python2才能执行,否则会导致yum不能正常使用,需要分别修改/usr/bin/yum和/usr/libexec/urlgrabber-ext-down这两个文件,把他们的#! /usr/bin/python修改为#! /usr/bin/python2。
然后还要给python3的pip3做一个软连接: ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3。
注意!如果你用了python3那么上面那个脚本就会有很大的变动。
参考资料
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html

